


研究内容
大規模データの可視化に関する研究
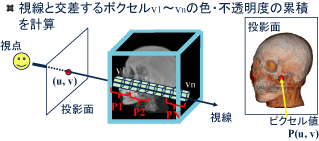
X線CT装置などの計測機器の発展により,大規模なボリュームデータが次々と生成されつつあります.また,流体力学などの計算科学の分野においても,計算機の高速化に伴い,大規模なシミュレーションが可能になっています.このような大量の情報を直感的に理解するためには,その可視化が不可欠です.その可視化の高速処理や新しい見せ方について研究しています.
キャッシュ最適化による高速ボリュームレンダリング
GPUを用いてボリュームレンダリングを高速化する手法として,テクスチャに基づく手法が広く用いられています.この手法においてデータ参照の局所性を高め,キャッシュヒット率を向上する手法を開発しました.評価の結果,もっとも効果の高い視点のおいてヒット率を50%から80%に高め,フレームレートを4倍に向上できました.

Cache-aware, In-place Rotation Method for Texture-based Volume Rendering
Yuji Misaki, Fumihiko Ino, and Kenichi Hagihara
IEICE Transactions on Information and Systems, Vol.E100-D, No.3, pp.xx-xx, (2017-03). - [PDF]
Copyright©2017 IEICE. This is the original publication available at IEICE Transactions Online http://dx.doi.org/10.1587/transinf.2016EDP7178
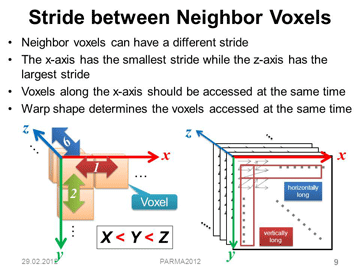
Improving Cache Locality for GPU-based Volume Rendering
Yuki Sugimoto, Fumihiko Ino, and Kenichi Hagihara
Parallel Computing, Vol.40, No.5/6, pp.59-69, (2014-05). - [PDF]
Copyright©2014 Elsevier B.V. This is the author’s version of a work that was accepted for publication. Changes resulting from the publishing process, such as peer review, editing, corrections, structural formatting, and other quality control mechanisms may not be reflected in this document. Changes may have been made to this work since it was submitted for publication. A definitive version was subsequently published at http://dx.doi.org/10.1016/j.parco.2014.03.013
Improving Cache Locality for Ray Casting with CUDA
Yuki Sugimoto, Fumihiko Ino, and Kenichi Hagihara
In Proceedings of the 25th International Conference on Architecture of Computing Systems Workshops (ARCS 2012 Workshops), Lecture Notes in Informatics P-200, Gesellschaft für Informatik, pp.339-350, Munich, Germany, (2012-02). Presented at the 3rd Workshop on Parallel Programming and Run-Time Management Techniques for Many-core Architectures (PARMA 2012). - [PDF]
Copyright©2012 Gesellschaft für Informatik.
データ圧縮による4次元データの高速ボリュームレンダリング
時系列の3次元データに対する高速なボリュームレンダリング手法を開発しています.主記憶に乗り切らないような大規模データに対し,ディスクから主記憶,主記憶からビデオメモリまでのパスをパイプラインとみなし,圧縮手法と組み合わせた圧縮パイプラインをソフトウェアで実装しています.これにより512×512×512ボクセル程度の大きさであれば,そのタイムステップ数に関わらず,実時間レンダリングが可能であることを示しました.
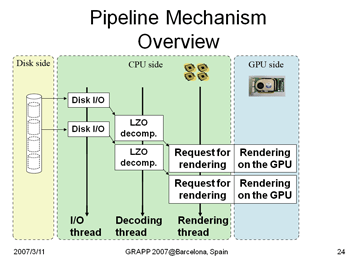
A Decompresion Pipeline for Accelerating Out-of-Core Volume Rendering of Time-Varying Data
Daisuke Nagayasu, Fumihiko Ino, and Kenichi Hagihara
Computers and Graphics, Vol. 32, No. 3, pp. 350-362, (2008-06). 24 Graphics Selection, Annual Report of Osaka University, Academic Achievement 2008-2009. - [PDF]
Copyright©2008 Elsevier B.V. This is the author’s version of a work that was accepted for publication. Changes resulting from the publishing process, such as peer review, editing, corrections, structural formatting, and other quality control mechanisms may not be reflected in this document. Changes may have been made to this work since it was submitted for publication. A definitive version was subsequently published at http://dx.doi.org/10.1016/j.cag.2008.04.007

Two-Stage Compression for Fast Volume Rendering of Time-Varying Scalar Data
Daisuke Nagayasu, Fumihiko Ino, and Kenichi Hagihara
In Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia (GRAPHITE 2006), pp.275-284, Kuala Lumpur, Malaysia, (2006-11). 研究会版は情報処理学会グラフィクスとCAD研究会 2005年度優秀研究発表賞. - [PDF]
Copyright© ACM, 2006. This is the author's version of the work. It is posted here by permission of ACM for your personal use. Not for redistribution. The definitive version was published in the Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia, http://dx.doi.org/10.1145/1174429.1174478
不透明度情報の共有による並列ボリュームレンダリング
ボリュームレンダリングの並列化は,1台の計算機では格納できないくらいの大規模なデータを可視化する際に不可欠です.この並列ボリュームレンダリングにおける課題の一つとして,本来画面に表示する必要のない部分の処理を省略することが挙げられます.この省略を実現するために,不透明度情報を計算機間で効率よく共有でき,負荷分散機能を持つ並列化手法を開発しました.評価の結果,従来の並列版を100として66の実行時間を達成しました.
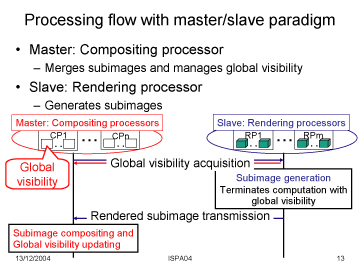
Parallel Volume Rendering with Early Ray Termination for Visualizing Large-Scale Datasets
Manabu Matsui, Fumihiko Ino, and Kenichi Hagihara
In Proceedings of the 2nd International Symposium on Parallel and Distributed Processing and Applications (ISPA 2004), Lecture Notes in Computer Science 3358, Springer-Verlag, pp.245-256, Hong Kong, China, (2004-12). 国内シンポジウム版は最優秀論文賞, 最優秀若手研究賞. - [PDF]
Copyright©2004 Springer-Verlag. The original publication is available at www.springerlink.com. http://www.springerlink.com/content/lmk08wmuc19aq6m5/
並列ボリュームレンダリングのための画像合成の高速化
並列ボリュームレンダリングでは,レンダリング部分を各計算機が独立に計算します.したがって,その部分は台数を増やせば増やすほど短い時間で処理できます.しかし,計算結果を通信で1台に集めないことには,最終画像は得られません.この画像合成部分は,台数の増加とともに遅くなってしまいます.この部分を高速に処理するための手法を開発しました.一つは従来手法の改良であり,空白部分の除去やデータ圧縮を駆使します.もう一方は,画面分割によるもので,通信の必要な組を削減することで,台数に対する耐性を得ます.
Memory Efficient Load Balancing for Distributed Large-Scale Volume Rendering Using a Two-layered Group Structure
Marcus Wallden, Stefano Markidis, Masao Okita, and Fumihiko Ino
IEICE Transactions on Information and Systems, Vol.E102-D, No.12, pp.2306--2316, (2019-12). - [PDF]
Copyright©2019 IEICE. This is the original publication available at IEICE Transactions Online http://dx.doi.org/10.1587/transinf.2019PAP0003

An Improved Binary-Swap Compositing for Sort-Last Parallel Rendering on Distributed Memory Multiprocessors
Akira Takeuchi, Fumihiko Ino, and Kenichi Hagihara
Parallel Computing, Vol.29, No.11/12, pp.1745-1762, (2003-11). - [PDF]
Copyright©2003 Elsevier B.V. This is the author’s version of a work that was accepted for publication. Changes resulting from the publishing process, such as peer review, editing, corrections, structural formatting, and other quality control mechanisms may not be reflected in this document. Changes may have been made to this work since it was submitted for publication. A definitive version was subsequently published at http://dx.doi.org/10.1016/j.parco.2003.05.015

A Divided-Screenwise Hierarchical Compositing for Sort-Last Parallel Volume Rendering
Fumihiko Ino, Tomomitsu Sasaki, Akira Takeuchi, and Kenichi Hagihara
In Proceedings of the 17th International Parallel and Distributed Processing Symposium (IPDPS 2003), Nice, France, (2003-04). 10 pages (CD-ROM). 研究会版は映像情報メディア学会 第5回研究奨励賞. - [PDF]
Copyright©2003 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE. http://dx.doi.org/10.1109/IPDPS.2003.1213090